
How to Build a Prospect List That Actually Converts: Our Proven 4-Step Process


In this post:
Most businesses and outbound sales pros struggle with prospect-list building because they go for quantity instead of quality.
What we mean is that most teams lean entirely on the popular B2B data tools. Apollo.io, Lusha, LinkedIn Sales Navigator, SalesIntel, and their likes. These tools have their place, but they are jacks of all trades and masters of none.
So teams pull thousands of contacts that barely match their ICP, and then sales reps burn weeks chasing leads that were never going to convert.
A high-converting prospect list is not about contact volume. It is about using the right process and the right tools to find the right people and the right contact details for them.
In this post, we will walk through the system we use at Nebor to build, qualify, and refresh a prospect list that actually drives revenue instead of soaking up SDR hours.
By the end, you will have every data point you need to put a real list in front of your team, ready for outbound.
Let’s get started.
TL,DR: here’s what your prospecting list workflow should look like
Here’s what the process should look like for building a prospecting list.
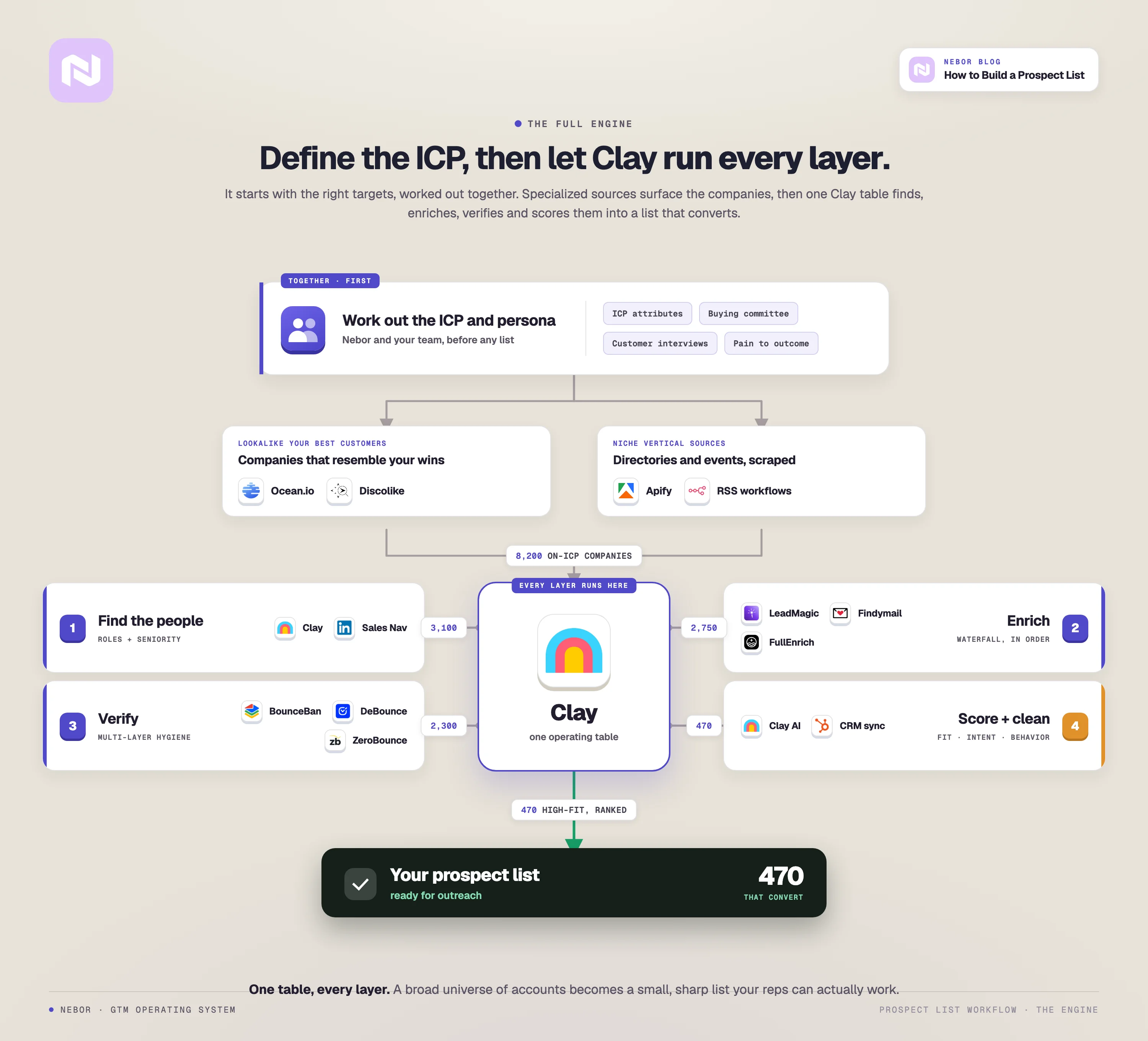
Why most prospect lists rot within three months
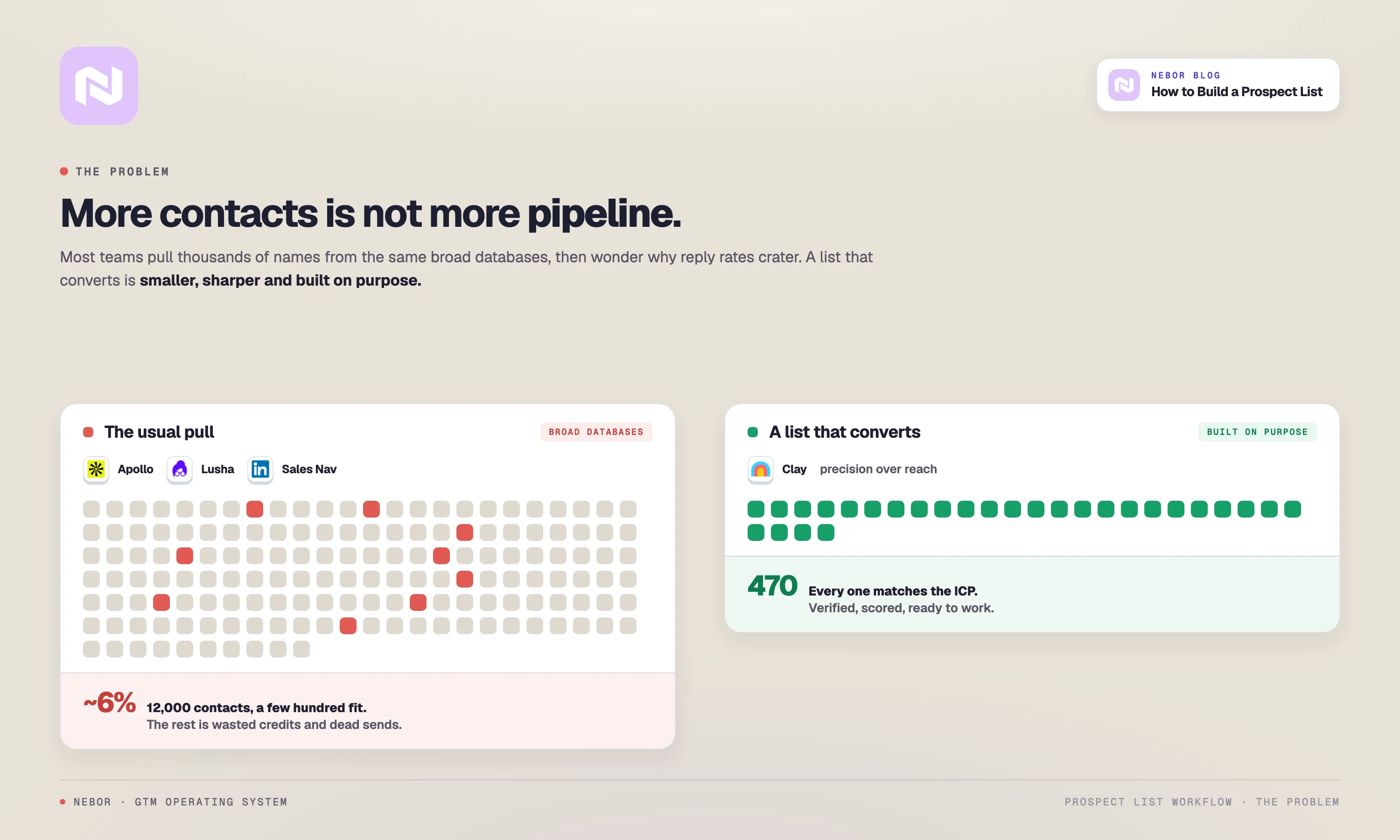
Before the workflow, the diagnosis.
Most prospect lists fail for the same three reasons, and skipping over them means whatever you build next will rot just as fast.
The first reason is quantity-first sourcing from generalist databases. Apollo and Sales Nav both work, but only as one layer. Teams treat them as the whole answer, pull a 50,000-row export, and tell themselves they have a list.
What they actually have is the same list every other vendor in their category is working from, with the same contact data, the same out-of-date job titles, and the same long tail of barely-qualified accounts.
The second reason is single-vendor enrichment. One enrichment provider is not enough to find the right people inside an account, get a working email, and land a mobile number. Each vendor has gaps.
A waterfall of two or three providers stacked on top of each other catches what each individual one misses. Teams that lean on one source ship lists with 30 to 40 percent bad data and never figure out why their reply rates collapsed.
The third reason is no refresh cadence. A list that was 100 percent accurate the day it was built decays roughly 30 percent per year. Job changes, company moves, email format swaps, role retitles. They all chip away.
Without a refresh workflow running on top of the list, six months in you are emailing ghosts. Fix those three and the rest of this post does its job. Skip them and the workflow below will produce the same rot, just faster.
We have written more on the structural shift this requires in our article on why most teams should automate sales prospecting end-to-end, and on what intent data actually is and how to use it, both of which sit underneath the workflow we are about to walk you through.
First, understand who you are selling to before you build a list
Before you collect a single contact, you need a real picture of what an ideal customer looks like for your business. That picture is the foundation. Without it, your list is a guess dressed up as a strategy.
A clear definition of who you sell to does two things at once. It keeps your team from burning hours on accounts that were never going to convert, and it focuses energy on the prospects with real potential. Both matter, and the second one is what compounds.
So that is where you start.
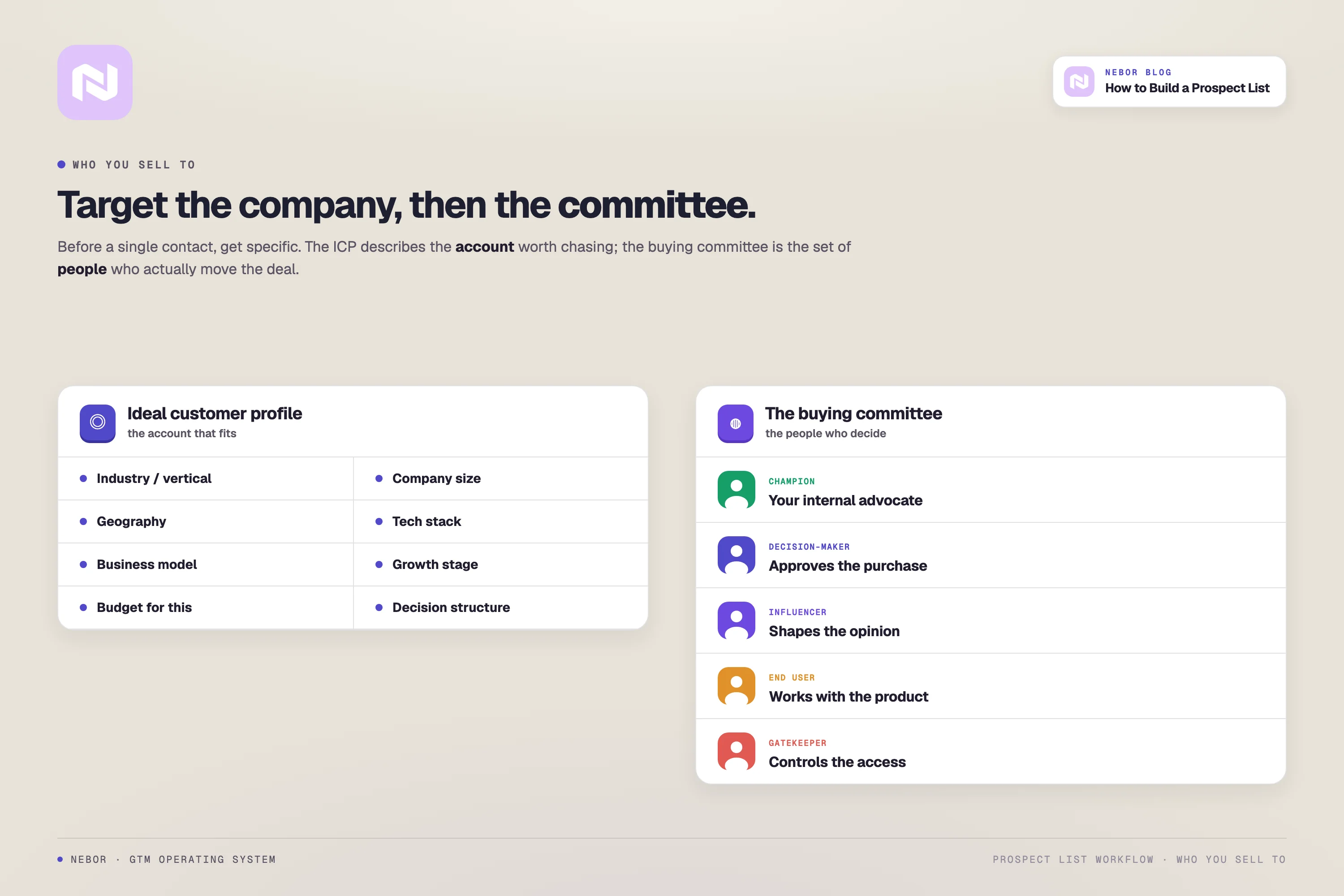
Define your ideal customer profile (ICP)
Your ICP is the type of company that gets the most value from what you sell, and that gives the most value back to your business. Get this right and your conversion rate moves before you change anything else in the funnel.
To build one, look at your best existing customers and pull out the patterns. The attributes that matter most are usually:
Company size by employees, revenue, or market cap
Industry or vertical
Geographic location
Tech stack or infrastructure (worth checking against BuiltWith or Wappalyzer when relevant)
Business model (B2B, B2C, marketplace)
Growth stage and trajectory
Budget for solutions in your category
Decision-making structure
Then go one layer deeper. Look at what made your strongest customers successful with your product, how they actually used it, what they tried before they found you, and what daily problem they kept running into.
Those patterns show you the real shape of the buyer, and they shape every choice you make further down the workflow.
A good move when you are getting started is to pull your customer database and rank by retention plus revenue.
Look at the longest-staying, most profitable accounts and ask what makes them different from the one-time buyers and the ones who churned. That comparison is where most ICPs sharpen.
The ICP also feeds the next thing you need to size, which is your full TAM. We have a separate post on how to build a TAM that holds up under outbound and the role it plays in keeping the list honest.
Build a real buyer persona
The persona is how you understand the people behind the titles. Their motivations, their concerns, how they prefer to be talked to, what they need to see before they say yes.
Based on what you sell, who in the organization actually has the authority to decide? That is your starting persona. In complex B2B sales, it is rarely one person. It is a buying committee, and the committee usually includes:
Champions who advocate internally for your solution
Decision-makers who hold the budget and sign off
Influencers who shape opinion in the room
End users who will work with your product daily
Gatekeepers who control access to the decision-makers
Mapping these roles inside a target account is what lets you tailor outreach instead of carpet-bombing the company.
When you build personas, work from data, not assumptions. The way we do this at Nebor is to interview our clients' current customers, their lost prospects, and a handful of industry experts.
We ask about their role, their KPIs, their career goals, the sources they trust for information, the daily responsibilities that take their time, and how they actually evaluate buying decisions.
What we listen for is the evaluation framework they use, which is the actual set of criteria that matters when they make a buying call. Is it price, implementation time, integration with their existing stack, scalability, support quality, time to value?
Those answers tell you exactly how to position what you sell when the outreach lands.
Map the value of what you sell to what the buyer is trying to do
Once you know who you are selling to, the next step is to draw a clean line between what your product delivers and what the buyer is trying to achieve. That alignment is what makes your outreach worth opening.
Identify the pain points your product actually solves
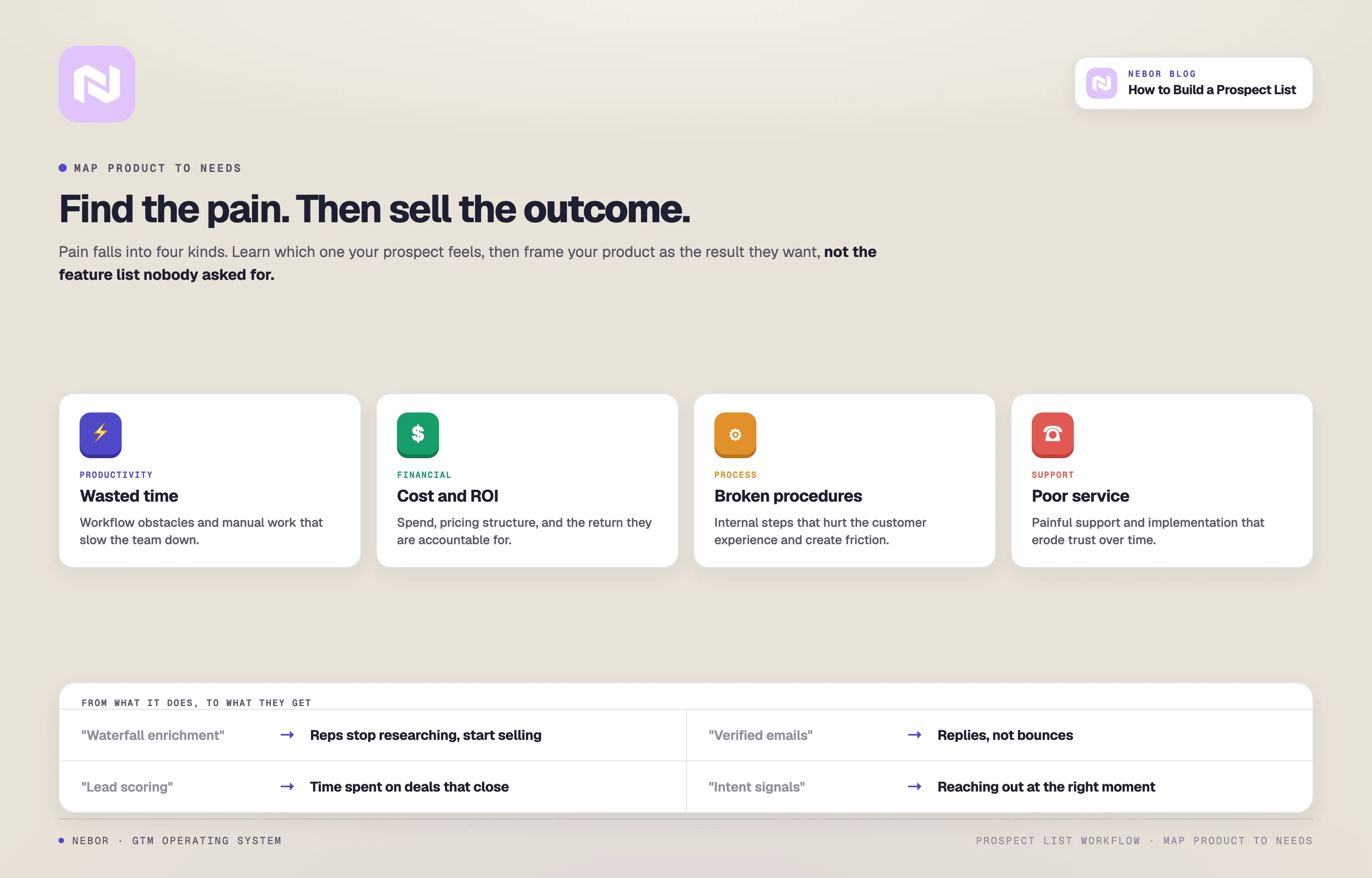
Conversion starts with naming the problem your prospect is already feeling. Pain points usually fall into four families:
Productivity pains. Workflow friction, tool gaps, or efficiency loss
Financial pains. Cost concerns, pricing structure problems, ROI uncertainty
Process pains. Internal procedures that slow down or break the customer experience
Support pains. Service interactions that fall short or onboarding that stalls
To find these honestly, you need more than one research method. Direct customer interviews give you depth and let you follow threads as they appear.
The people inside your company who talk to customers every day, your sales reps, your support team, your marketing leads, see things in the data that nobody else sees. Pull from both sources before you call the picture complete.
As you collect what they tell you, look for the patterns. Recurring frustrations across many conversations are the bedrock of your value proposition.
You can run the conversations through ChatGPT to find clusters faster, but the human pass matters too. Patterns you spot yourself stay sharper than patterns a model surfaces.
These shared problems are what shape how you talk about what you sell. If you skip them, your outreach will read like a feature list. But if you get them right, then the prospect will feel seen right from the first sentence.
Match features to buyer goals, not the other way around
Your product is only valuable to the extent it helps the buyer get where they are trying to go. Features in isolation mean nothing to the buyer. The outcomes those features produce for them are the only thing that does.
For every feature, ask two questions. How does this solve a specific problem in the prospect’s day? And what is the bigger business outcome they get when that problem goes away.
That second question is the one most teams skip. The shift from “what our tool does” to “what the buyer ends up with” is what separates outreach that books meetings from outreach that gets ignored.
We wrote more on this shift in the best ways to generate B2B leads, if you want our longer discussion on this.
Size your TAM before you build the list
Most teams skip this and pay for it later. Your lead list always inherits its ceiling from your TAM.
If you build a list against a TAM you have not actually sized, and you will either overshoot (a 50,000-row spreadsheet of half-fits that buries your team) or undershoot (a 400-row list that runs dry in three weeks).
A real TAM is not a guess. It is the count of every company in the world that fits your ICP closely enough to plausibly buy. Once you have that number, every downstream choice gets easier.
You know how aggressive your filters can be. You know whether the ICP holds enough volume to support the pipeline target your team is on the hook for. You know whether to widen the segment, sharpen it, or stack a second one on top.
The mistake we see most often is teams starting with whatever the data tools give them and calling that the TAM. Apollo says there are 18,000 companies that fit your filter, so you treat 18,000 as the universe.
The problem is that Apollo’s universe is not the entire universe. It is the slice Apollo can see, with the firmographics Apollo has, mapped to the filters Apollo lets you set. The actual market is usually larger and more segmented than that.
The way we build TAM at Nebor starts from the ICP definition above and works outward through several data sources stacked on top of each other. Apollo and Sales Nav give you the baseline. Industry-specific directories give you the long tail. Triangulation between the two is what produces a number you can defend in front of your CFO.
We have a fuller post of this in our post on building a TAM that holds up under outbound, with the exact stacking logic.
One more practical note. Sizing the TAM is also where you find out your ICP is wrong.
If the count comes back at 600 companies for an enterprise motion that needs 3,000-account coverage, you have a positioning problem, not a sourcing problem.
Better to find that out before you spend two weeks building a list against it.
How to build the prospect list (the workflow that actually holds up)
With ICP, persona, value-outcome, and TAM in place, you finally have the right scaffolding to build the list itself. This is the operational core.
From here on out, it is choosing the right data sources, finding the right people inside those companies, enriching with multiple providers, verifying for deliverability, and putting the whole thing on a refresh cadence.
Step 1: Choose your data sources based on ICP complexity, not popularity
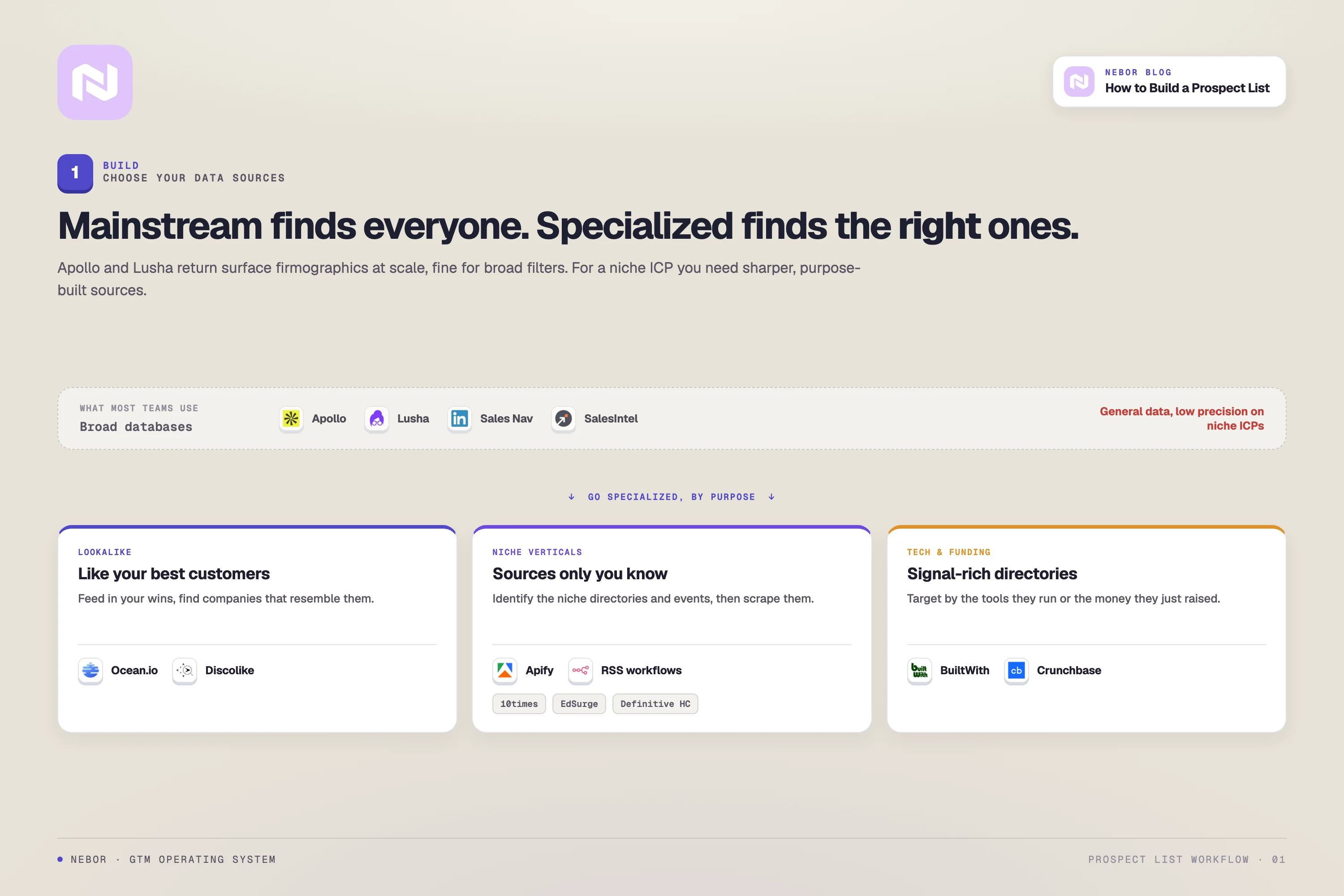
The default move is to lean on Apollo, Sales Nav, Lusha, or ZoomInfo and call that the data layer. Search “best prospecting tools” and the same five names come up. They work, but only as one piece of the puzzle.
The problem is that these tools all draw from overlapping sources of firmographic data. They are built for the broad strokes.
Like, if your ICP is “companies generating over $1M ARR using HubSpot in North America”, they handle it well.
But if your ICP is “companies running a warehouse over 500 square meters that hosts a customer-facing event in the next quarter”, they fall apart. The granular filters do not exist, and the data behind them does not either.
Here is how we think about the data layer at Nebor.
Use the generalist databases as the starting layer because they’re not the whole answer
Apollo and Sales Nav give you a clean firmographic baseline. Use them to draw a wide first cut against your ICP. Industry, company size, region, basic tech stack signals, role density. Pull what they offer, and treat that pull as 50 percent of the universe.
The point is to use them for what they are good at. A generic filter on a known segment, run quickly, with reliable contact data on the obvious ICP fits. What you should never do is mistake their data universe for yours. Treat the export as the floor.
Layer industry-specific data on top to find the rows the generalists missed
This is where most teams stop. It is also where the list separates from every other list your competitors are running.
The pattern is to find the public directories, association membership lists, conference attendee lists, and trade publications that already aggregate the companies in your space.
Then scrape them into Clay tables and merge them into your master list. A few examples we have used:
10times for finding companies attending or hosting B2B events in a specific industry
EdSurge for EdTech company coverage and funding signals
Definitive Healthcare for rich profiles on healthcare providers and hospitals
BuiltWith and Wappalyzer for tracking which sites run which technology
Crunchbase for funding rounds, leadership changes, and venture data
Almost every industry has its equivalent. Funeral homes have public registries. Farms have agricultural associations. Manufacturing plants have trade body memberships.
Most of these are not behind a paywall. They are sitting on a public web page waiting for you to scrape them.
The tool we run all of this through is Clay, which lets us pull from any URL via HTTP, parse the response into structured columns, and merge against the Apollo or Sales Nav baseline in the same table.
We have written about why most Clay implementations fail before they get to this stage, if you want a more elaborated read.
When you need an AI-driven lookalike layer, build it inside Clay
Sometimes the right move is to start with a list of your best 20 customers and ask the system to find more companies that look like them.
You won’t need to buy a separate “AI prospecting” tool. You can build it inside Clay using Claygent and a structured research prompt against the company URLs, fed by your enrichment waterfall.
The reason we prefer this is ownership. A standalone AI prospecting tool is a black box that disappears the moment you stop paying for it.
A Clay-native lookalike workflow will live in your account, run on your prompts, reference your real customer data, and can be tuned without a vendor in the loop.
What that means is that you get the same output and you keep the asset. We have written more on the broader case for the best data source tools to run sales and lead gen with.
The pattern we recommend across all of this is that your data layer should always have at least two sources stacked on top of each other.
Generalist databases combined with industry-specific scraping is the most common combination, and adding the Clay-native lookalike layer on top makes sense when the ICP is unusual enough to need it.
One source is never enough, and the teams who treat one source as enough are the teams whose lists rot fastest.
Step 2: Find the actual people inside those companies and enrich the contacts
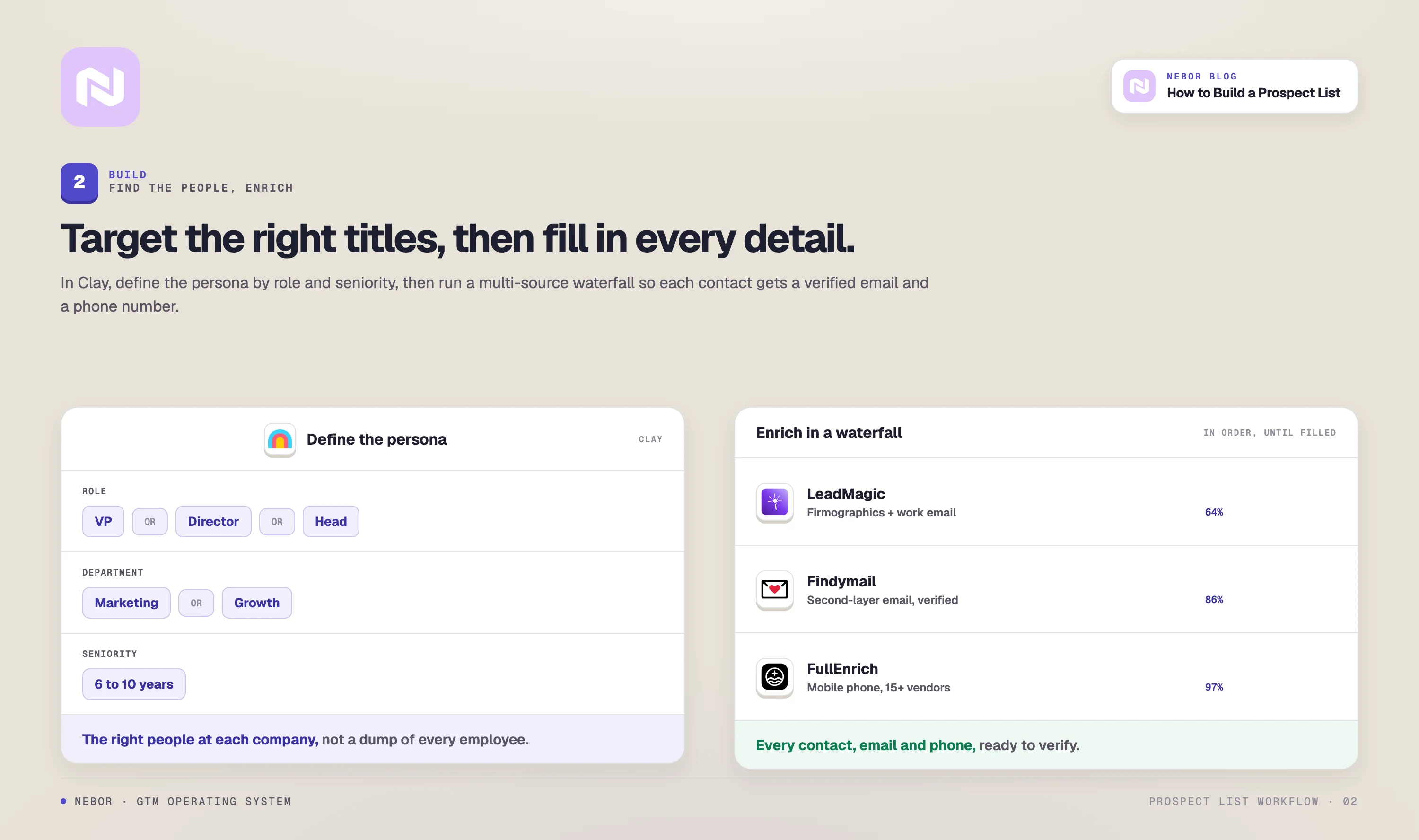
You have a list of companies that fit your ICP. The next job is harder. You need to find the right people inside each one, get a working email, and ideally a mobile number. This is the step where most prospect-list builds either become real or quietly break.
Reaching out to the wrong person at the right company does not just waste a touch. It poisons the next touch too. The decision-maker you actually wanted will see the thread and assume you do not know who runs what. So the bar on this step is high.
Here is how we run it at Nebor.
Run the people-finding workflow inside Clay, against the companies you already have
Once your company list is sitting in a Clay table, layering in the right contacts is a single workflow you build once and reuse forever.
The setup we run:
Push your company list into Clay either via CSV or a direct integration with whichever data source produced it
Set up an enrichment column that pulls people from each company by role, seniority, and department
Configure multi-layered search parameters that handle role variation. Something like “VP OR Director OR Head” combined with “Marketing OR Growth OR Demand Gen”
Add seniority and tenure filters so you avoid the people who just joined and have no signing authority
The reason this works is that Clay treats enrichment as a layered pipeline instead of a single lookup. Every column is a separate provider call. If one provider misses, the next one catches.
If you are working with a data source that doesn’t directly give you information on the people, we recommend you use LeadsFactory.io in Clay. It’ll basically fill that gap for you. You’ll find the people and their contact.
Stack three enrichment providers
This is where the biggest gain in Step 2 comes from. One provider gives you 60 to 70 percent coverage on a typical list. Three providers stacked in a waterfall give you 90+.
The three we run as our default stack:
LeadMagic as the firmographic and role-discovery layer. LeadMagic enriches with company-level firmographics, finds the right people by role and department, and returns the LinkedIn profile URL alongside the basic contact data.
This is usually the first call in the waterfall because it is fast and broad.
Findymail as the verified-email layer. Findymail takes the name and company domain produced by the first call and returns a verified professional email.
We run this second because the verification piece reduces bounces before the next, more expensive provider gets called.
FullEnrich as the mobile-number and hard-cases layer. FullEnrich aggregates contact data from 15+ premium vendors and is where you go for mobile numbers, hard-to-find profiles, and the rows the first two layers missed.
It is the most expensive of the three, which is why it sits last. The waterfall logic only calls it for the rows that still have gaps after LeadMagic and Findymail have done their work.
The reason to run them in sequence rather than in parallel is cost discipline. Each provider call costs credits. Sequencing means you only pay the more expensive providers for the rows the cheaper ones could not handle.
Set up the waterfall once in Clay, point it at any company list, and the cost-per-enriched-contact stays under control without you babysitting it.
Why the “just outsource it to Fiverr” path is the wrong move
Most teams hit Step 2, look at the cost and complexity, and decide the practical answer is to throw the brief over the fence to a Fiverr or Upwork freelancer.
Twenty dollars an hour, a hundred-row spreadsheet back in three days, done. We get why teams do this. We have also seen it fail every time.
There are three structural reasons it breaks.
The first is no refresh cadence. A freelancer hands you a CSV. The CSV is a snapshot. The moment they hit send, the data starts decaying.
Six weeks later, you have no way to refresh it without paying again, and there is no automation in your account to do it for you. The work walks out the door with the freelancer.
The second is no QA layer. A Clay waterfall has the verification logic baked in. It catches bounceable emails, flags catch-all addresses, and checks mobile numbers.
A freelancer working in a spreadsheet does none of that, no matter how careful they are. The deliverability damage shows up two weeks into the campaign, when your sender reputation has already taken the hit.
The third is no workflow ownership. After the engagement ends, you are left with a one-off list and zero capability to run the same job again. There is no system in your stack, no playbook your team learned, no asset that compounds for the next campaign.
The next time you need a list, you start over from zero.
We have written more on this pattern in why outsourcing lead generation no longer makes sense for B2B teams, and on why Clay-native workflows beat the outsourced-vs-in-house-SDR debate entirely.
The Fiverr path looks cheaper because the invoice is smaller. It is more expensive in every way that matters once you measure refresh, QA, and what you actually own at the end.
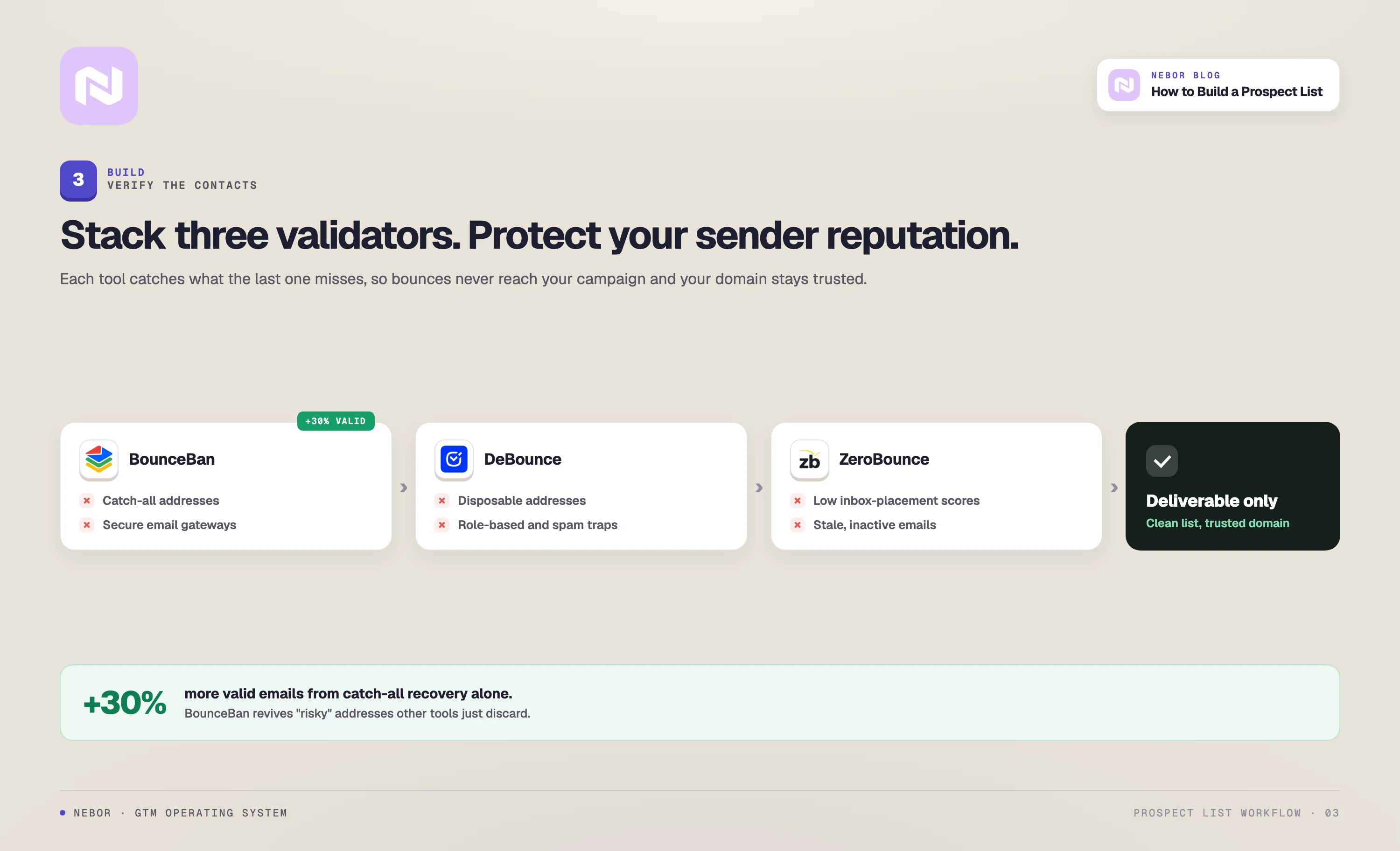
Step 3: Verify the contacts before they ever touch a sequence
Finding the contacts is one job. Confirming they will actually deliver is another.
If you skip this step, the bounces will hit your sender reputation, your domain warm-up unwinds in a single bad campaign, and you will lose three months of inbox placement to undo what one bad list did.
Even when you outsource the contact-finding to a freelancer (which we just argued you should not), this is the step that has to stay in-house. You should always run multiple verification layers on every list before any sequence sees it.
Here is the three-provider verification stack we run, in this order:
BounceBan as the catch-all and Secure Email Gateway (SEG) layer. BounceBan is unusually good at the hardest category in email verification, which is the catch-all addresses and the inboxes sitting behind Secure Email Gateways.
On a typical list it recovers 25 to 30 percent more usable emails than the standard verifiers do, by actually validating the risky catch-all addresses instead of marking them all as unsendable.
DeBounce as the second-layer scrub. DeBounce runs a different validation logic in real time or in bulk, identifies invalid addresses, removes disposables, filters out role-based emails, and checks against blacklists and DNS records.
We use it as the cross-check on what BounceBan returned, which is how we catch the edge cases either tool would miss alone.
ZeroBounce as the activity-and-scoring layer. ZeroBounce adds a deliverability score that predicts inbox placement, a separate AI-based catch-all detector, and an activity-level signal that tells you whether the inbox has been used recently.
The activity signal is the one that earns its place in the stack, because dormant inboxes look valid to a standard verifier and still tank your reply rate.
Running all three sounds like overkill. It is not. Email verification is the single most important piece of the workflow because every downstream metric that will justify your success or lack thereof depends on it.
We have written more on the underlying mechanics in our deliverability guide for outbound teams, if you want the full breakdown of why this matters.
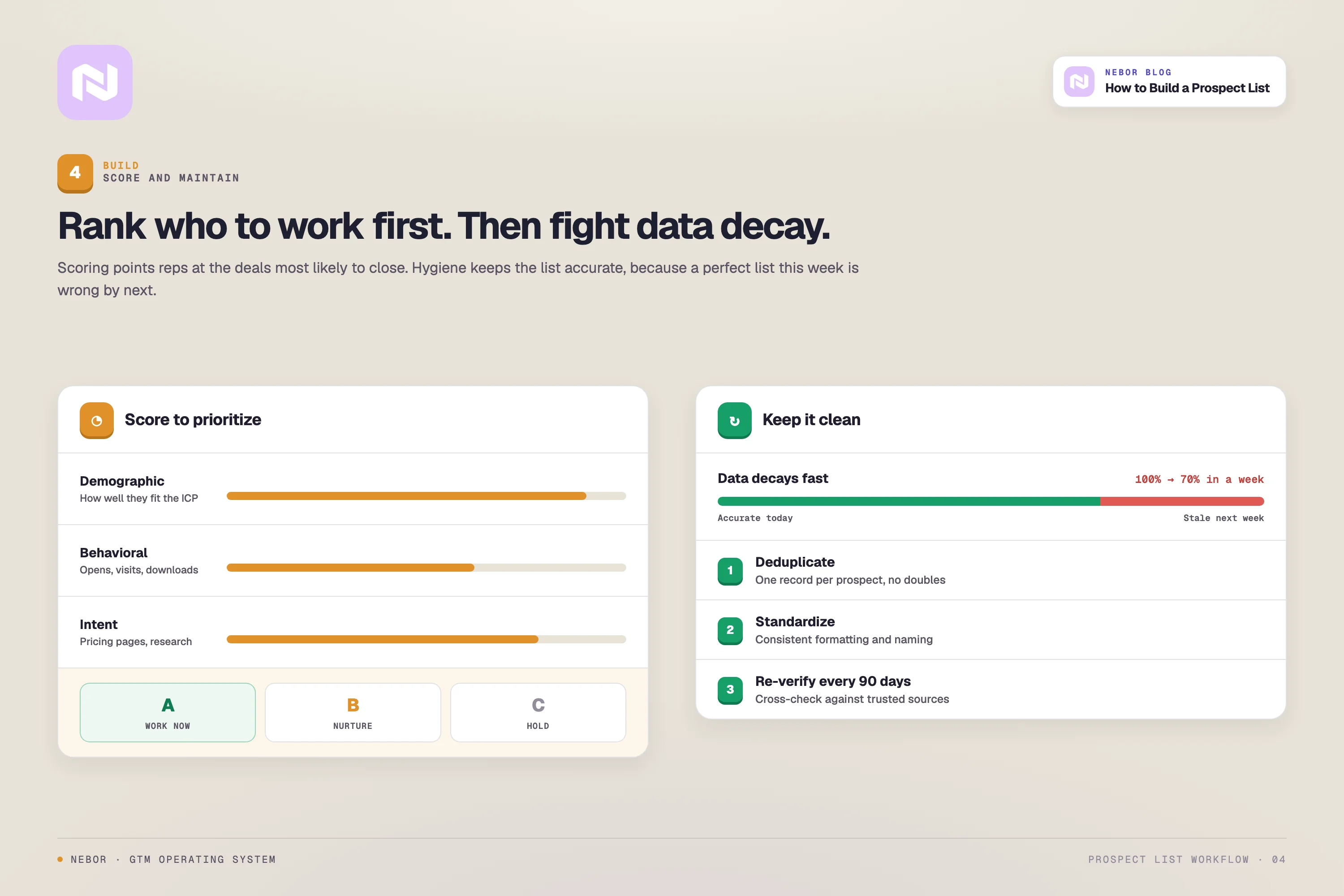
Step 4: Score the leads and put the list on a refresh cadence
You have an enriched, verified list. The last job is to prioritize it and keep it alive. Both pieces tend to get skipped, and both are why the list rots six weeks in.
Lead scoring is the only way to spend SDR time on the right rows
Lead scoring assigns a number to every contact based on how likely they are to convert. The point is to focus the team’s outreach hours on the rows with the most pipeline potential, instead of working the list top-to-bottom and treating every account the same.
The scoring systems that actually move the number combine three data types:
Demographic scoring, based on how closely the prospect matches your ICP attributes
Behavioral scoring, based on engagement signals like email opens, page visits, and content interactions
Intent scoring, based on direct buying signals like pricing-page visits, demo requests, or competitor research patterns
If your list lives in Clay, the scoring logic gets built once as a column formula that updates every time the row gets re-enriched.
Also, push the score into your CRM as a sortable field so that your reps can work the list in priority order without you having to police it. We have more on the underlying automation pattern in our piece on automating sales prospecting end to end.
Refresh cadence matters more than the original build
A list that was 100 percent accurate the day you built it loses roughly 30 percent of its accuracy per year. It’s a classic data decay rate.
Job changes, role retitles, company acquisitions, email format swaps, departures, mergers. The decay is constant and there is no way around it except a refresh workflow.
The cadence we run is to re-enrich every list quarterly at minimum and weekly for the high-priority tier.
Our re-enrichment runs the same Clay pipeline against the same rows, surfaces the changed fields, and hands the diff back to the team. It flags job changes as new opportunities and archives departures. It also catches all email format changes.
Three operational moves keep the list clean over time:
Deduplication. Catch redundant records before they create the awkward “two of our reps just emailed the same person” moment
Standardization. Hold to consistent formatting and naming so the scoring logic can actually parse the rows
Verification on a recurring schedule. Cross-check contact data against your providers every 90 days, even when nothing visibly changed
None of this is glamorous. All of it is what separates a list that produces pipeline for 18 months from a list that produces pipeline for six weeks.
Here’s what the entire workflow looks like when done right.
Layer intent signals on top of the static list to keep it sharp
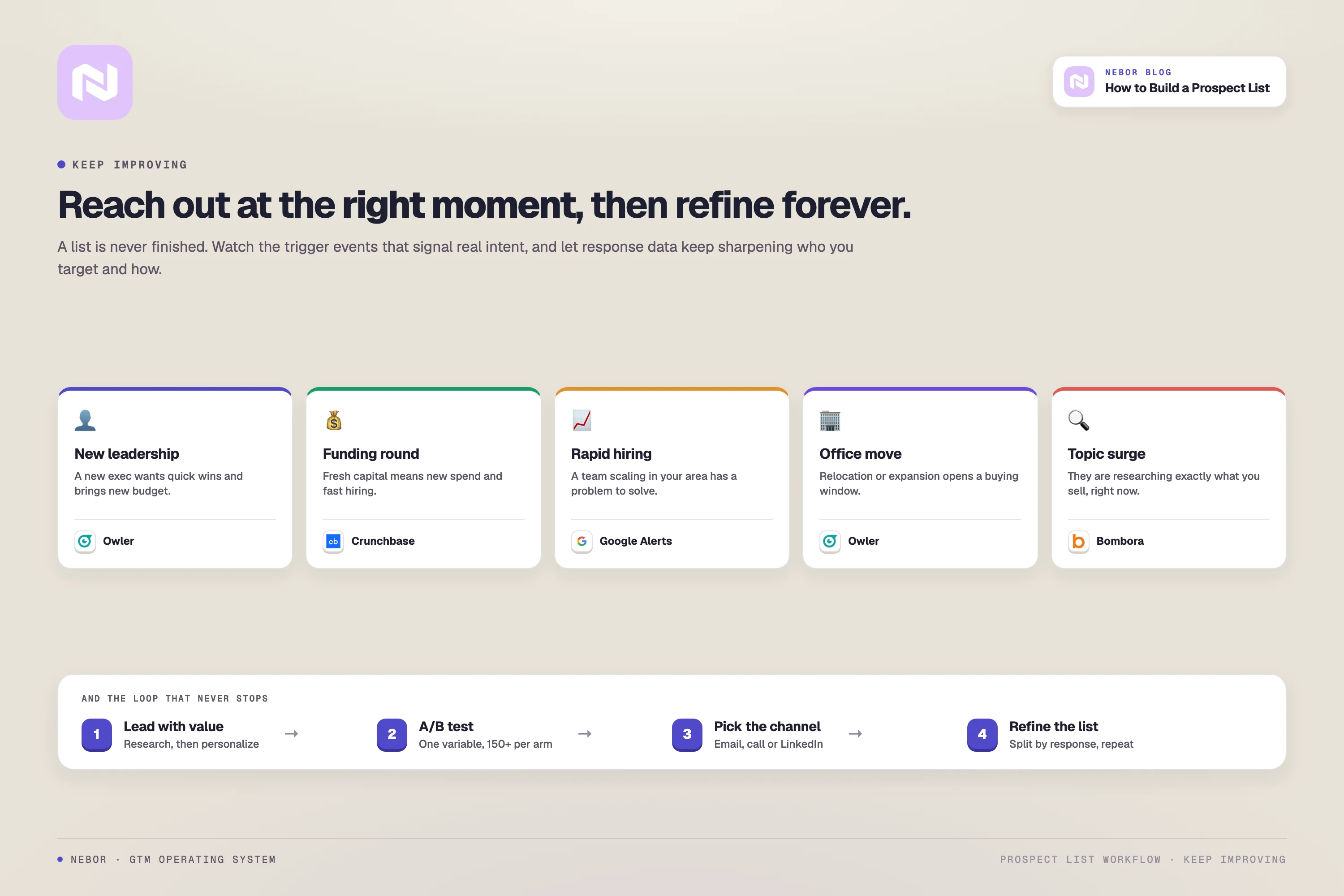
Everything above gets you a static list. Static lists, even good ones, decay. The way to compound the value of the work you just did is to layer intent signals on top so the prioritization keeps re-sorting itself based on what the accounts are doing in real time.
Intent signals come in three categories worth running in parallel.
Behavioral intent from third-party platforms. For example, we use PhantomBuster to monitor LinkedIn activity, post engagement, comment patterns, and other behavioral cues that flag when a prospect is signaling interest in your category.
When a Director of Sales at a target account starts engaging with content about your product, that is a signal worth catching.
Other tools in this category include Bombora for B2B research intent and G2 for buyer review activity, both worth feeding into the same Clay table.
Visitor de-anonymization on your own site. RB2B and Leadinfo reveal the companies and (in RB2B’s case, in the US) the individual people visiting your site.
A target account that hits your pricing page twice in a week without filling a form is one of the highest-quality signals you will ever get.
We have written on the workflow side of this in our walk-through of how to set up a website visitor tracking workflow that actually feeds the pipeline.
Trigger events from public web monitoring. Funding rounds, leadership changes, expansions, hiring waves in a specific department, product launches, office moves.
All of these are public information and all of them indicate buying readiness. The way to catch them at scale is to set up an RSS-feed monitoring workflow that watches your TAM continuously.
We built one we use across clients and wrote it up in our piece on RSS-feed-driven intent monitoring.
The whole point of the intent layer is that it turns the prospect list from a snapshot into something that re-sorts itself every week.
Yesterday’s row 800 becomes today’s row 12 because something happened in the account that tells you “now is the moment”.
Without the intent layer, your team works the list in static priority order and misses the windows that open and close before the next refresh hits.
We talked about this in elaborated details in our article on what intent data is and how to use it.
The intent layer is also where the work compounds. A static list goes stale. A list with intent stacked on top gets sharper every week the system runs. Same rows, better priorities, more meetings booked off the same TAM.
Tips for getting the most out of the prospecting list once it is built
A good list is the input. Outreach quality is what determines whether it produces pipeline. A few patterns worth holding onto:
Lead with value, not features
The non-negotiable rule of cold outreach is to open on something specific to the prospect's situation. Generic personalization at the first-name and company-name level no longer clears the bar. The reader has seen 200 of those this month.
Real personalization references something that is true today about their business. A funding round, a hire, a product launch, a recent post they wrote, a competitor move that affects them.
Spend five to ten minutes on each high-value account before the message goes out, or build the research step into your Clay table so the system surfaces the angles automatically. Either works. What does not work is skipping it.
Track response and engagement so you know what to keep doing
The metrics that matter on a cold campaign are reply rate, positive reply rate, and meeting-booked rate, in that order. Open rates are noise (Apple Mail Privacy Protection killed open rates as a signal in 2021 and they have not recovered).
Set up tracking from the first send. Implement unique identifiers per campaign, sequence, and persona so you can compare like to like. Without that comparison, you cannot tell which messaging is working from which list segment is working, and you end up tuning the wrong variable.
A/B test one variable at a time, with sample sizes that hold up
A/B testing only earns its name if the test is clean. Change one variable at a time. Subject line, opener, CTA, send time. Not three of them at once.
Run each variant against at least 150 prospects so the result is something you can defend. Pull both versions during the same time window so day-of-week effects do not contaminate the read.
Refine the list in light of what the campaign tells you
Treat the list as a living thing. After every campaign, segment the rows into recipients, repliers, positive repliers, and bookers. Feed those segments back into your scoring logic.
The patterns that emerge over three campaigns sharpen the next list build in a way that no amount of upfront ICP work can match. The campaign data is the second draft of your ICP.
Match the channel to where the prospect actually pays attention
Cold email, cold call, LinkedIn touch, and event-driven outreach all work in different combinations for different segments.
Engineering buyers respond to technical depth in writing. Finance buyers respond to numbers in a short call. Marketing leaders respond to LinkedIn. There is no universal channel and there is no universal sequence.
The point is to test the channel mix against your specific ICP and let the data drive the answer.
Most teams converge on a multi-touch sequence with email leading, LinkedIn supporting, and a phone call as the third touch on the highest-priority rows. Use that as a starting point, then tune.
(For the intent-signal layer of the outreach decision, see the section above. It earns its own treatment because it is the part that compounds the list’s value over time, not just the campaign’s.)
Why you do not need a bigger SDR bench, and how Nebor takes the prospect-list workflow off your team’s plate
When teams come to us about lead-list problems, the diagnosis they walk in with is almost always wrong.
They think their problem is capacity. Their team cannot build the lists fast enough, the SDRs are buried in research instead of conversations, the new hire who was supposed to fix it left after six months. So they assume the answer is more headcount.
Capacity is not the problem. The problem is that the work the existing team is doing should not be done by humans at all.
Most of the hours your SDRs are losing to prospecting are hours spent doing what a properly built Clay workflow does in minutes, on a recurring schedule, without anyone touching it.
The fix is to take that work off your team’s plate entirely and give them back the hours for the part of the job humans are actually good at, which is reading replies, having real conversations with prospects, and getting meetings closed.
The way we do that at Nebor is by building three connected workflows that live in your accounts.
An intent workflow that runs continuously across your TAM and surfaces the buying windows the moment they open.
An outbound workflow that produces meetings without your team touching a list.
An inbound workflow that catches every warm signal before it goes cold.
Each one is built on the tools you already use or should be using. Each one runs on a refresh cadence so the work compounds. And each one stays in your account when the engagement ends, which is the whole point.
Here is how each one gets built, what it produces, and how the three fit together.
We build you an outbound system that produces meetings without your team touching a list
The outbound workflow is the one most directly tied to the post you are reading.
Every step we walked through above (TAM sizing, company sourcing, contact enrichment, verification, scoring, refresh) gets built into a single Clay-native pipeline that runs on a recurring schedule and feeds your sequencer with verified, prioritized, ready-to-send rows.
Here is what the build looks like in practice.
We start by mapping your real ICP and TAM with the depth your team probably skipped
Most ICP definitions we inherit from clients are surface-level. Industry, company size, region, maybe a tech-stack signal. That is not enough to build a workflow against.
Before we touch a tool, we run a working session that pulls apart your closed-won data, your churn data, your highest-LTV accounts, and the patterns inside them. The output is an ICP definition with the granular attributes the workflow can actually filter on.
Then we size the TAM properly. Apollo plus Sales Nav plus the industry-specific directories that matter for your space, triangulated into a single number you can defend in front of your CFO. This is the foundation. Every downstream filter inherits from this number.
We build the company-sourcing layer with three data sources stacked
Generalist databases for the firmographic baseline, industry-specific scraping via Clay HTTP for the long tail your competitors miss, and a Claygent-driven lookalike pass against your best 20 customers when the ICP justifies it.
All three feed into the same master Clay table, deduplicated and merged on company domain.
The output of this layer is a clean company universe. The size of the universe matches the size of the TAM you defined in the previous step, give or take a small variance.
We enrich and verify every contact through the multi-provider waterfall
LeadsFactory.io, LeadMagic, Findymail, FullEnrich for the contact stack. BounceBan, DeBounce, ZeroBounce for verification. Stacked in the cost-disciplined sequence we covered above.
The waterfall lives in your Clay account, runs on every new row that enters the table, and re-runs on a refresh cadence so the data stays alive.
We design the sequencing layer in Instantly and HeyReach and wire it into the table
Once the rows are enriched and scored, the table pushes them into Instantly for cold email and HeyReach for LinkedIn touches.
Personalization variables are written by the same Clay logic that built the row, so the message references something specific to the account by default.
We hand qualified replies back to your reps with full context attached
Replies route into your CRM (HubSpot or Salesforce, depending on what you run) with the full enrichment payload attached.
Your reps see the company, the persona, the score, the sequence the reply came from, and the context they need to walk into the conversation prepared. Their job is to have the call. Everything before that has already been done by the system.
The output of this whole workflow, in operational terms, is a continuous flow of qualified replies and booked meetings hitting your reps’ inboxes from a list that maintains itself.
We have written more on that idea in our blog post on building a GTM system that generates business on autopilot and on why most Clay implementations stall before they get to this stage.
We catch every warm signal coming through your existing channels and route it to the right rep with full context
Outbound is one half of the picture. The other half is what happens to the warm signals you are already producing today and quietly losing.
Most teams have a leaky inbound funnel, and they have it because nobody owns the workflow that catches the signals and routes them.
A demo request lands and gets handled by the first SDR who sees it, not the rep who covers that segment. A pricing-page visitor never gets a follow-up because nobody knew they came.
A senior buyer at a target account books a meeting and the rep walks into the call with no enrichment payload, no persona context, and no idea what the buying committee around them looks like.
Here is how we close that gap.
We instrument the inbound entry points and feed every event into Clay
Form fills, demo requests, meeting bookings, chatbot conversations, content downloads, webinar signups. Every entry point gets wired into the same Clay table so there is one canonical record of every warm signal that touched your pipeline.
The reason this matters is that inbound signals usually live in five different tools, and the rep who catches one rarely sees the other four. Centralizing them in Clay is what makes the routing logic possible in the first place.
We enrich the moment a meeting books
We set up your meeting tool to fire a webhook into Clay, the second a meeting is booked. Clay runs the same enrichment waterfall we built for outbound (LeadMagic, Findymail, FullEnrich) plus a buying-committee mapping pass with LeadsFactory that finds the other four to six people in the account who shape the decision around your buyer.
The output is a fully enriched account profile sitting in your rep's CRM record before the meeting starts. Persona, seniority, tech stack, recent funding, hiring signals, the buying committee around them. The rep walks into the call with the same context an account executive at an enterprise vendor would have.
We have written more on the mechanics in our walk-through of an inbound meeting workflow that surfaces the buying committee.


Related Articles



By clicking Sign Up you're confirming that you agree with our Terms and Conditions.
